|
  |
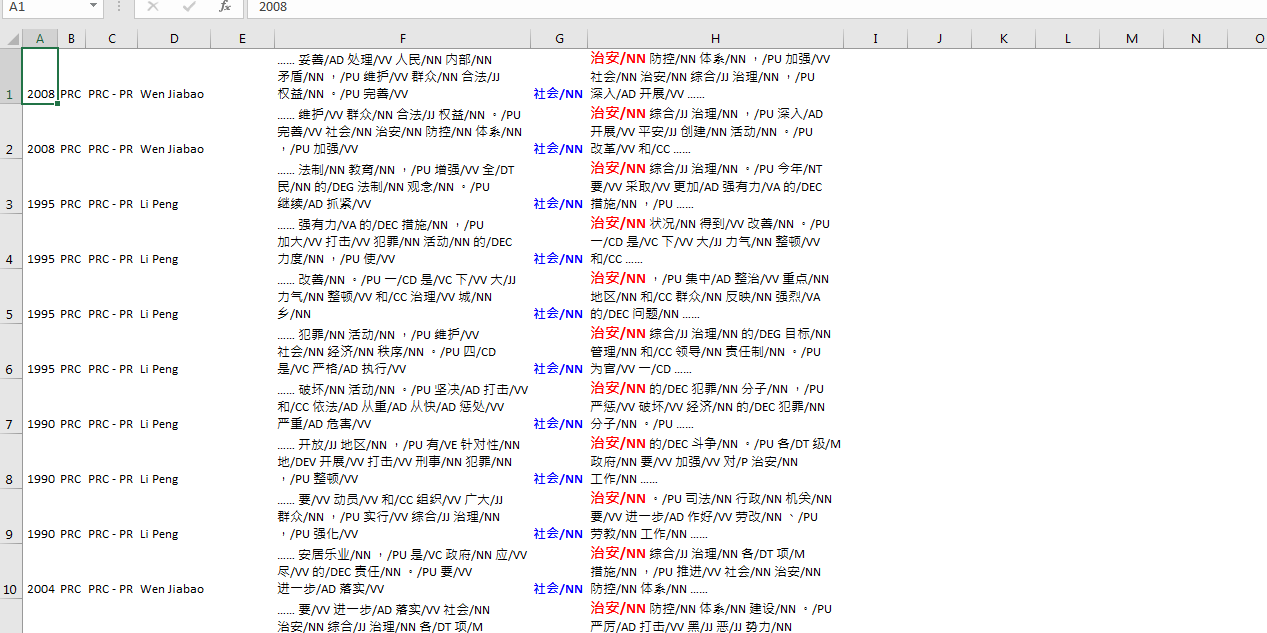
User Manual for the English Corpus
This is a manual for users to search the corpus. Users are free to select specific functions among the following steps according to the research needs.
Keyword Search
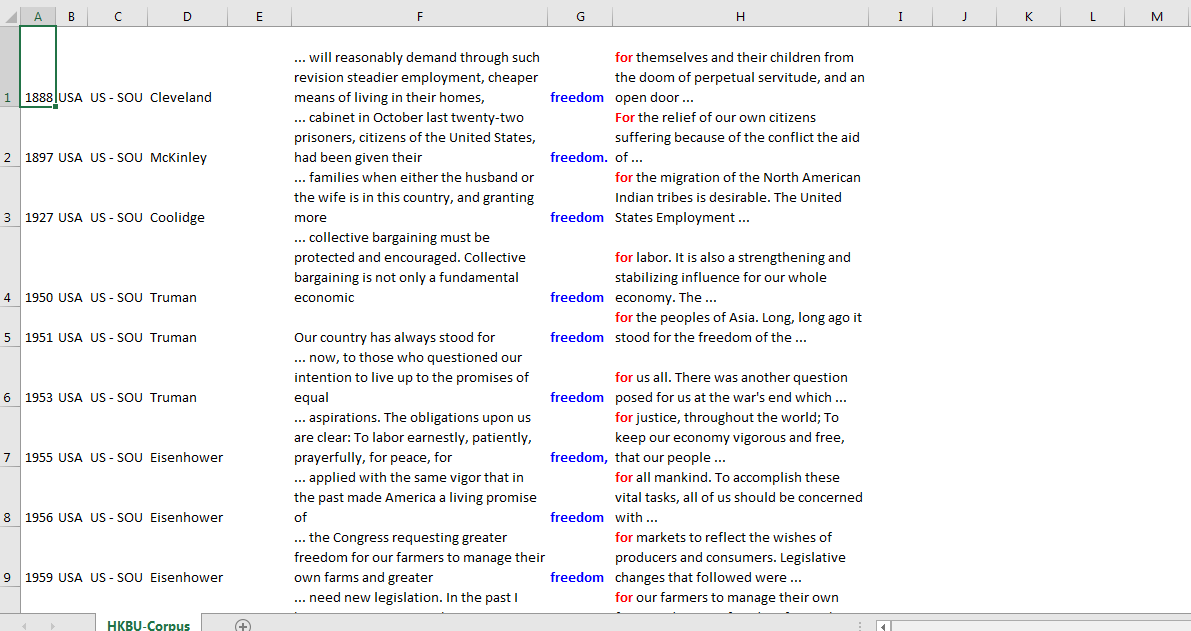
1. Input a word or phrase you want to search in the corpus, e.g. “freedom”.
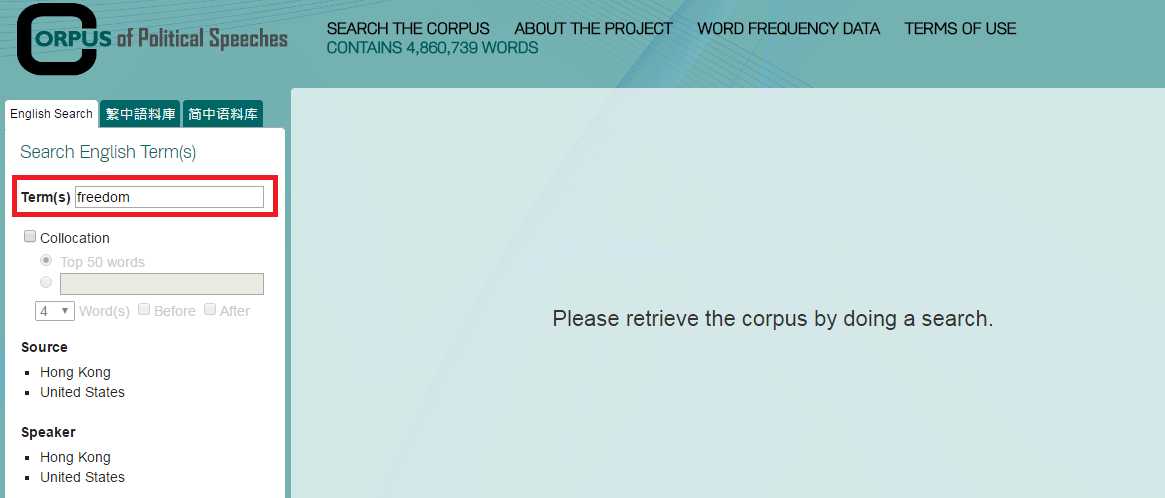
2. Click the Source needed, either Hong Kong or United States. Then check the relevant boxes to specify the sources you want to search.
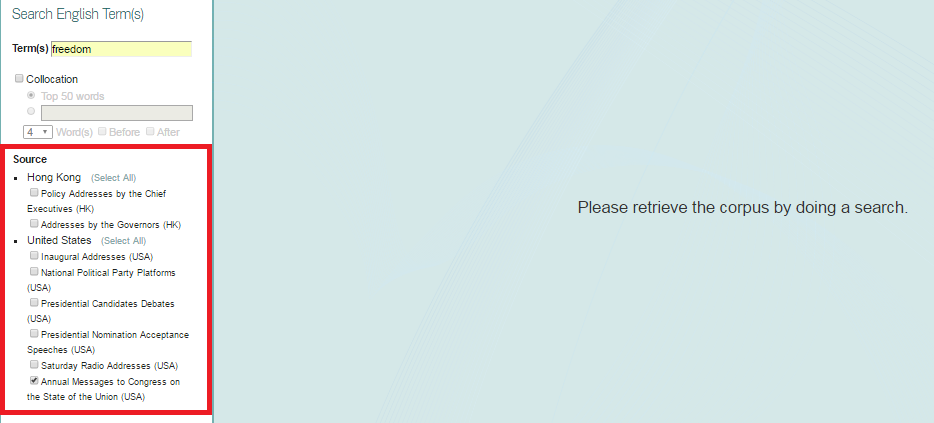
3. Click the Speaker needed, as shown below.
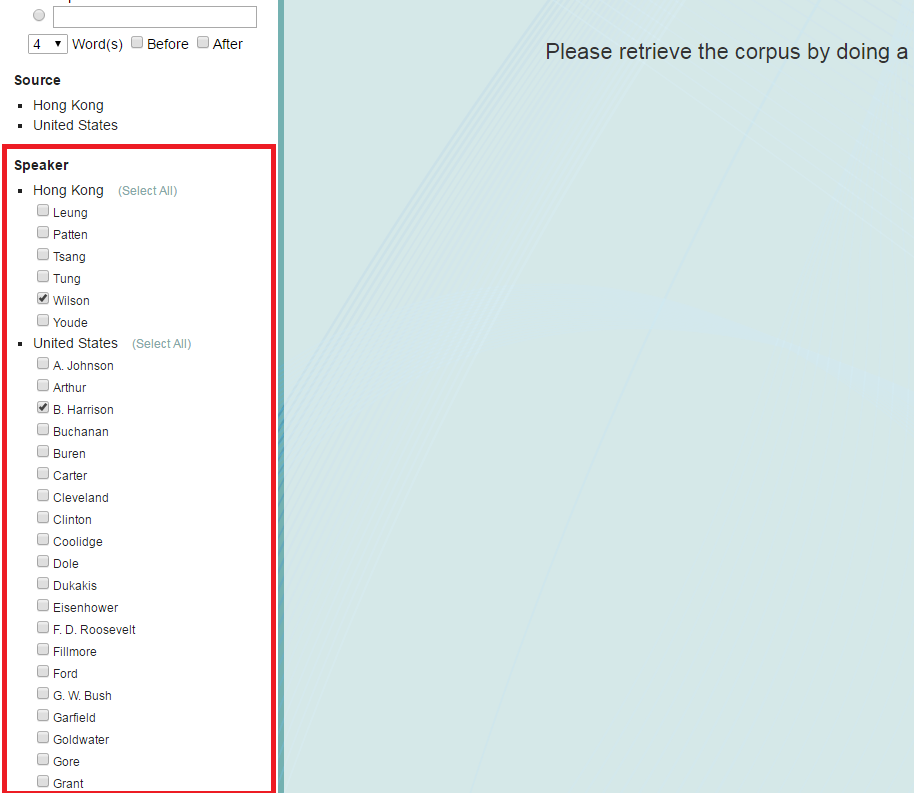
4. Choose the time range either by selecting the boxes or by dragging the green button to limit the retrieved data to a particular timeframe.

5. Press the Search button to get the result page.
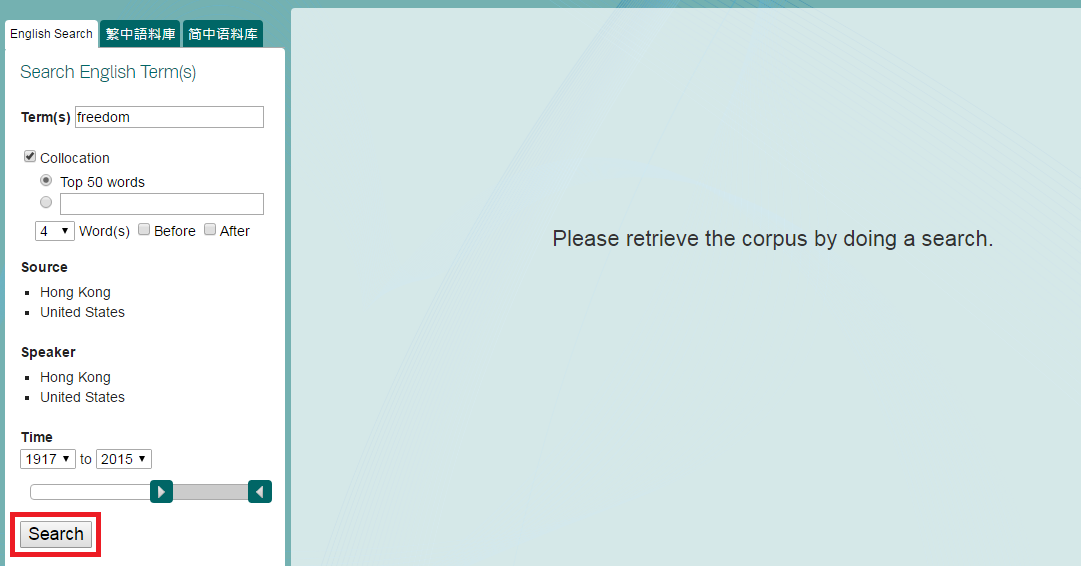
6. View your search results with both No. of Occurrence in the relevant corpora and Graphical Representation to show the relevant percentage among all the search results.
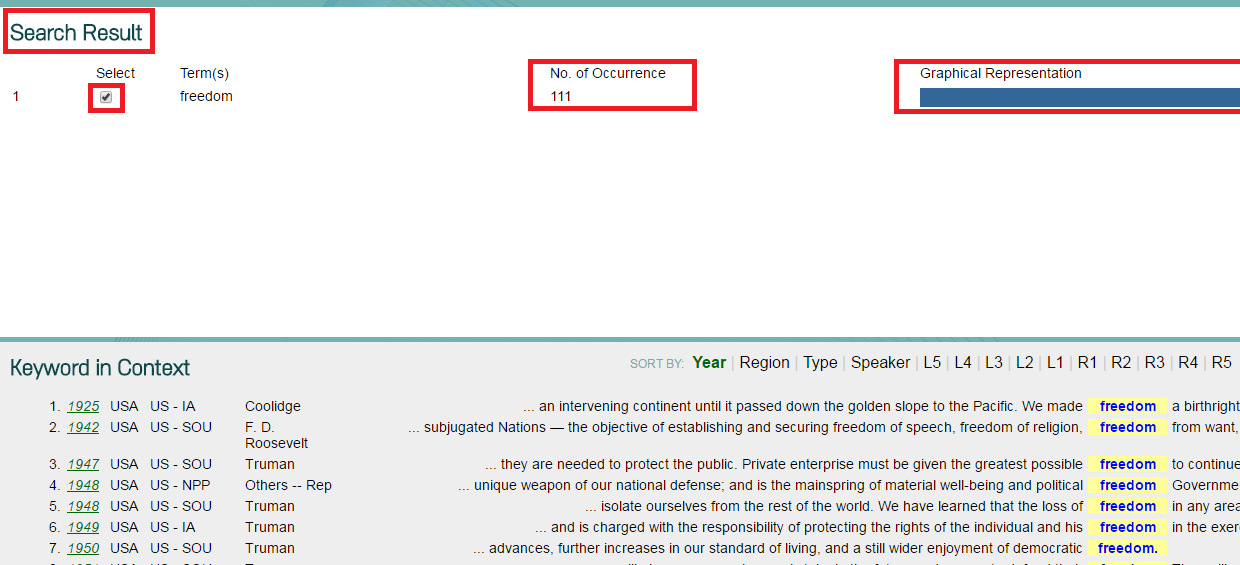
7. You can sort out the Keyword in Context by Year/Region/Type/Speaker.
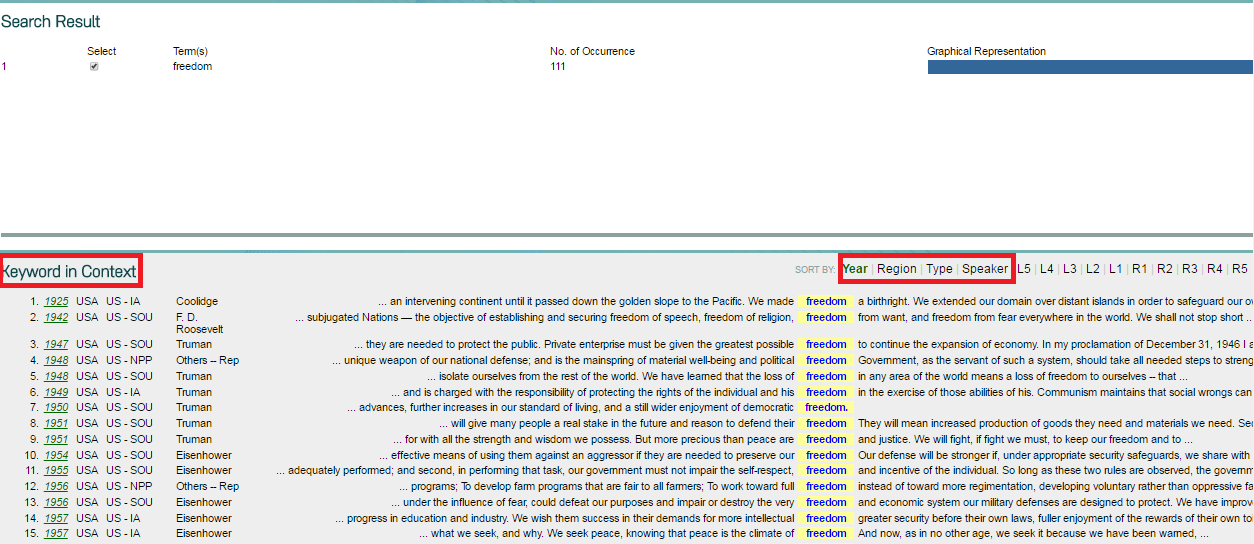
8. You can also sort out your Keyword in Context by L1-L5 & R1-R5 (e.g. L1 is the first word to the left of the keyword).

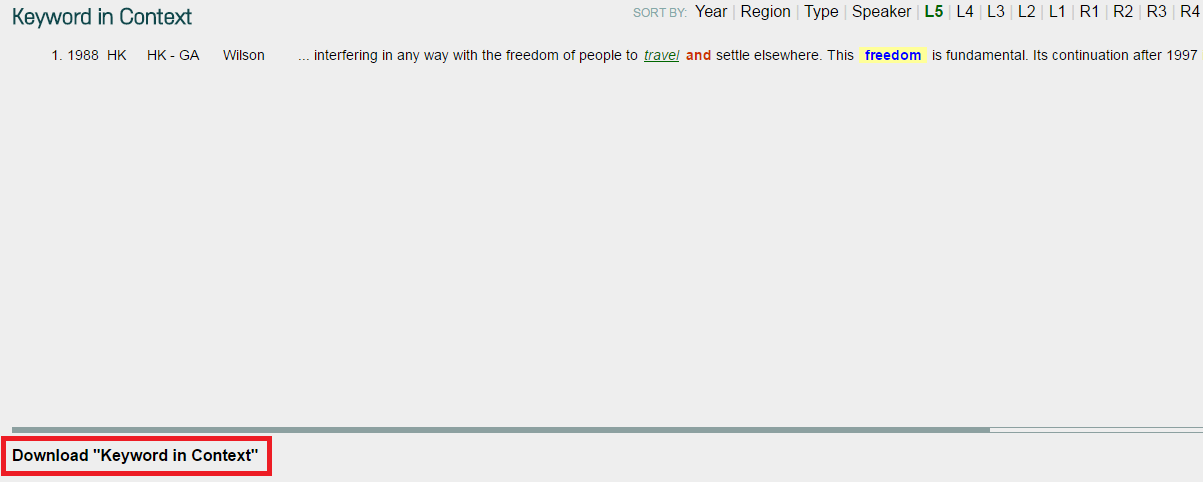
9. Click on any interested entries in step 8 to view Keyword in Expanded Context.

10. Click the button Download “Keyword in Context” to extract your data to an Excel document.
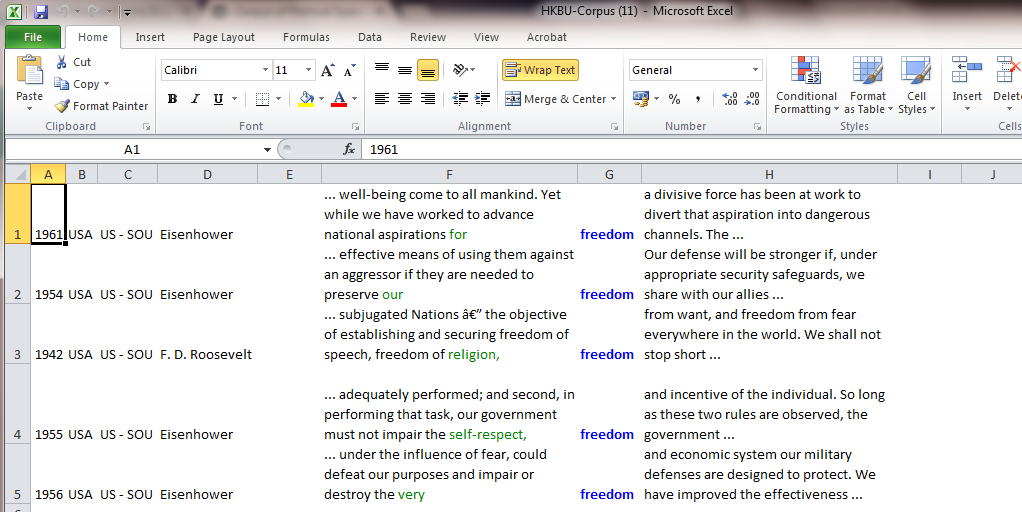
Collocation Function
Two approaches are available for the collocation function: Top 50 words, and the single collocate.
1. Top 50 words
a. Check the Collocation box, select “Top 50 words”, and then choose a number to specify its distance from the keyword, e.g. “1 & Before”.
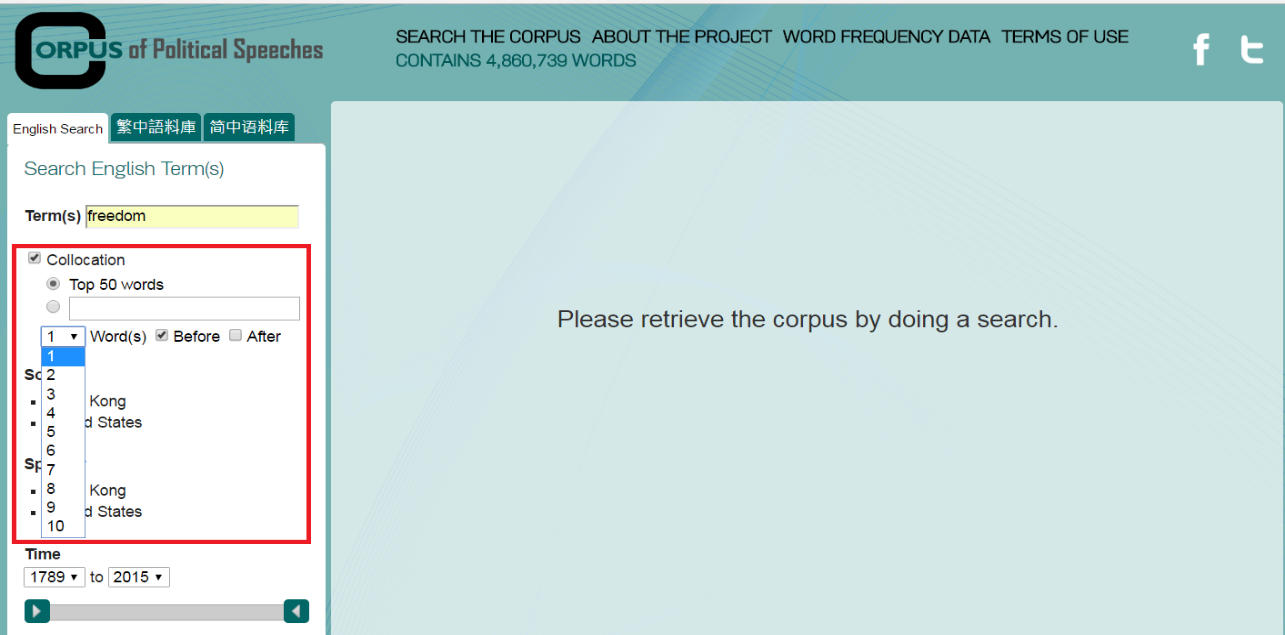
b. Similarly, choose and specify the source, speaker, and time to retrieve data according to your research needs, e.g. “the SOU corpus”.
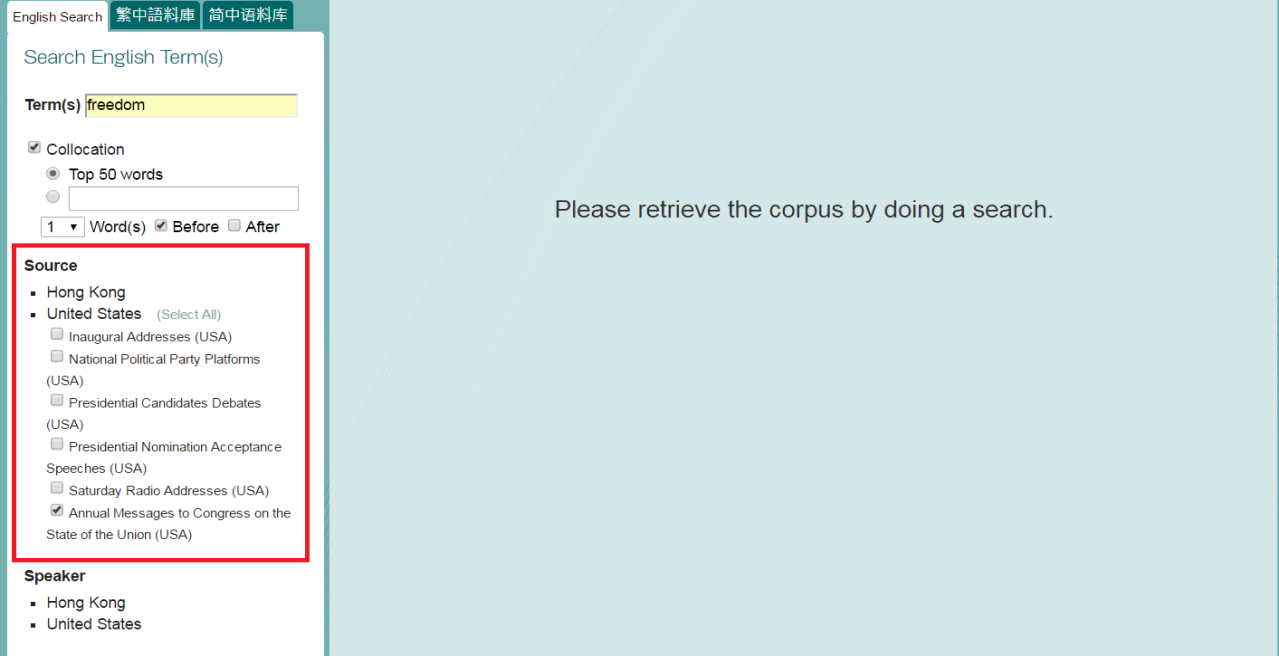
c. View your search results with both No. of Occurrence and Graphical Representation, and then choose a collocate you need.
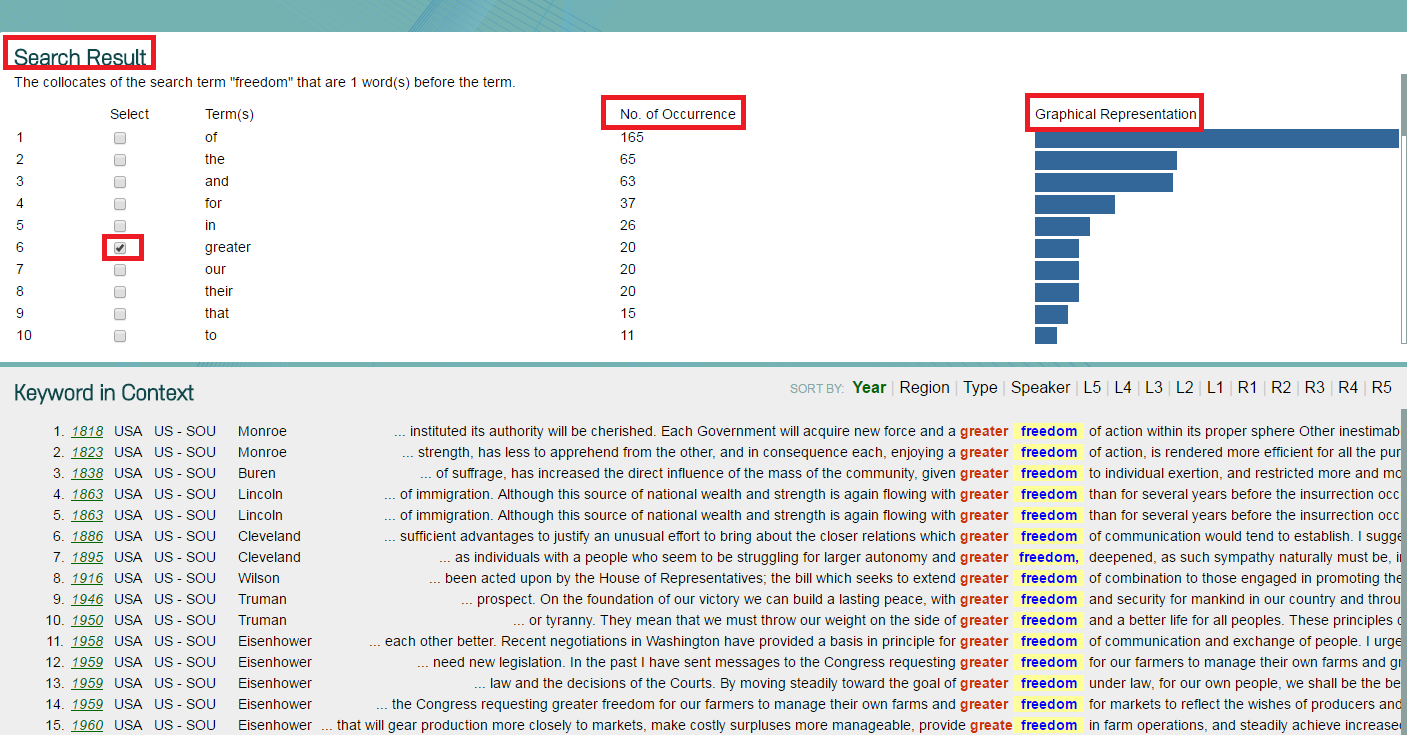
d. Output your results to Excel by clicking Download “Keyword in Context”.
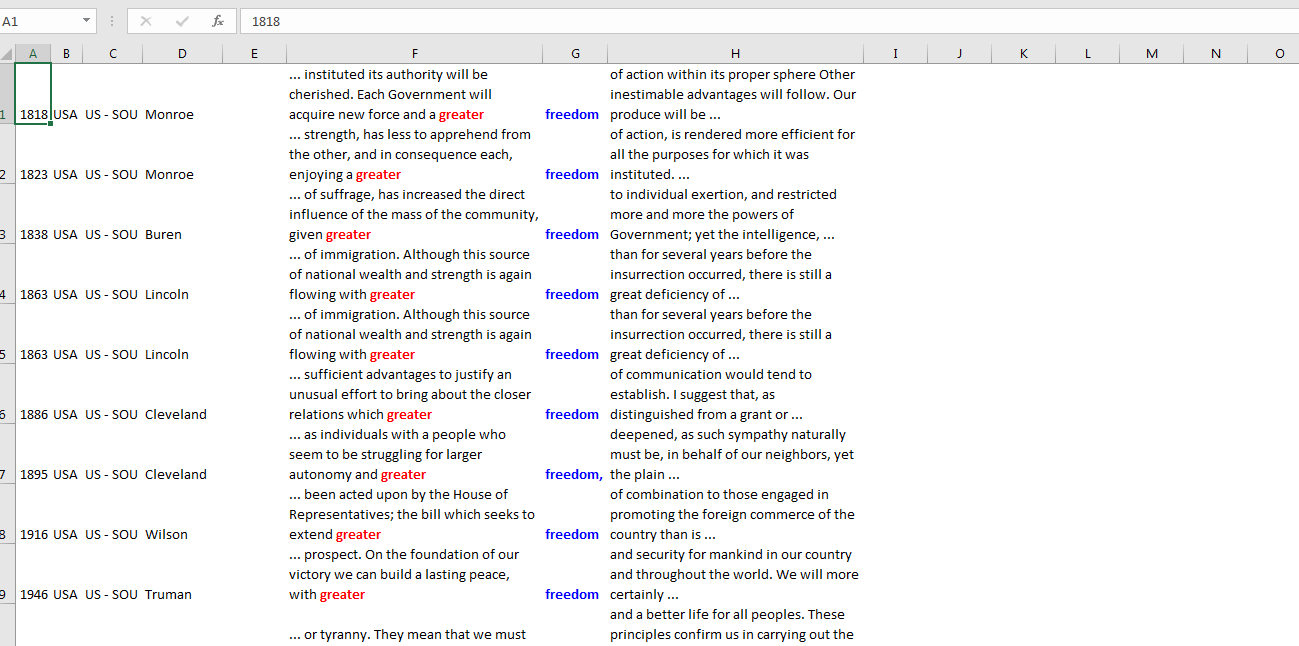
2. Single collocate
a. Check the Collocation box, input a single collocate, e.g. “for”, and then choose a number to specify its distance and position to the keyword, e.g. “1 & After”.
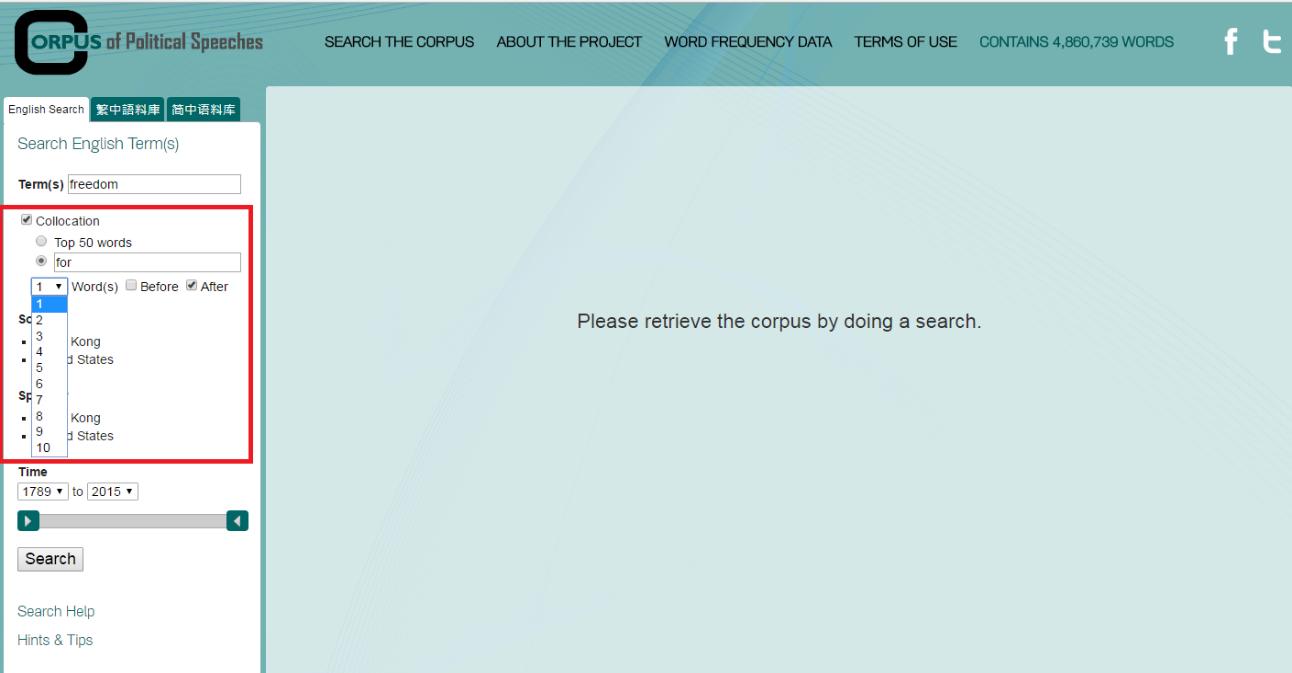
b. Similar to the previous guidelines, choose and specify the source, speaker, and time to retrieve data according to your research needs, e.g. “the SOU corpus”.
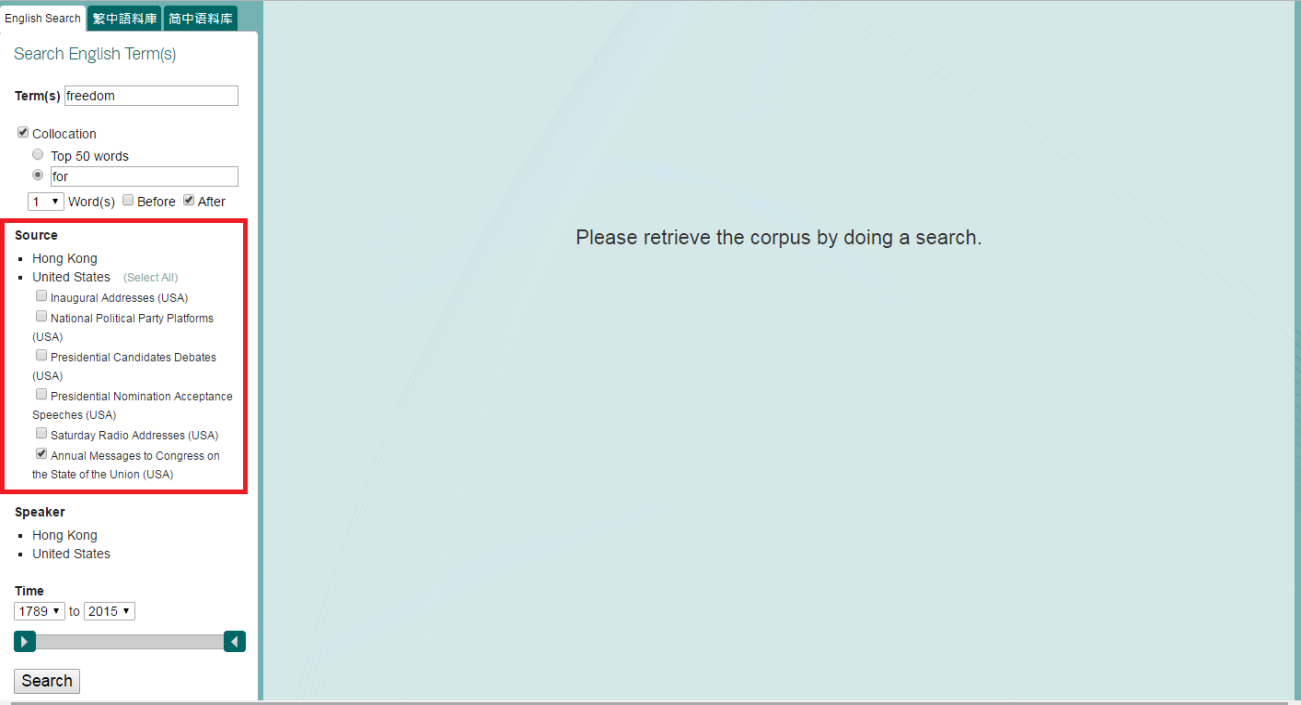
c. View your search results with both No. of Occurrence and Graphical Representation.
d. Output your results to Excel by clicking Download “Keyword in Context”.
User Manual for the Chinese Corpus
Keyword Search
1. Input a word or phrase you want to search in the corpus, e.g. “社会(society)”.

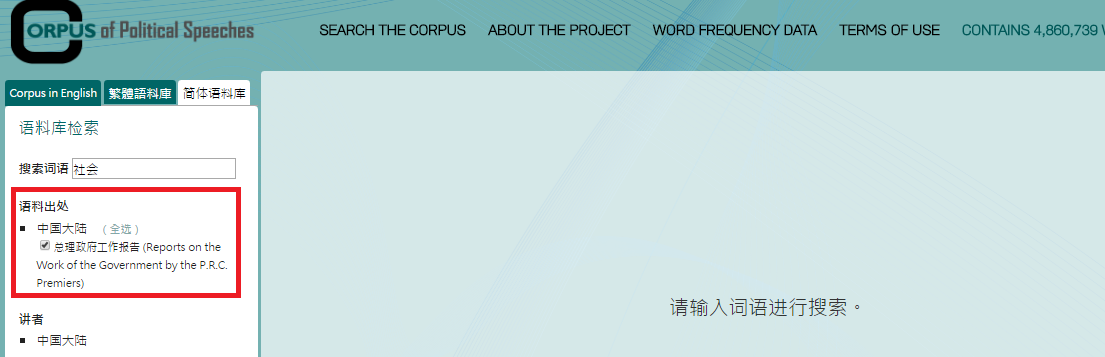
2. Click “语料出处(source)” needed.
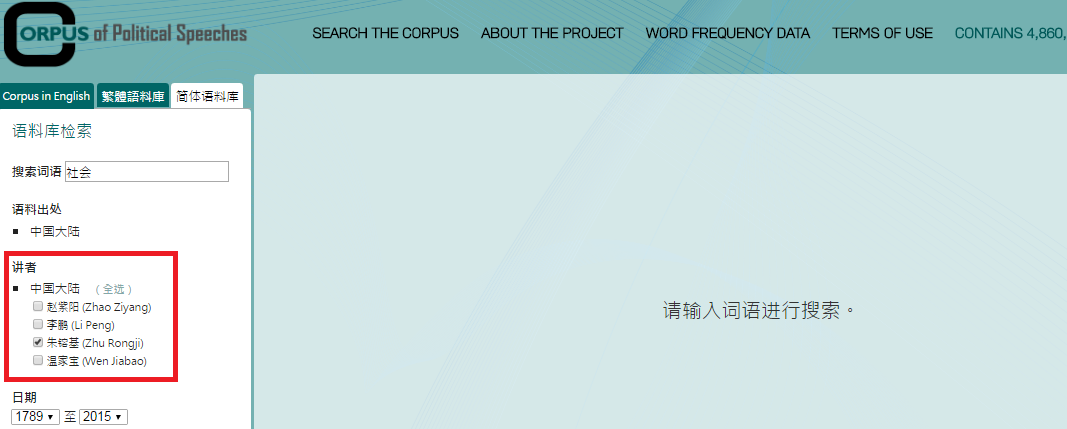
3. Click “讲者(speaker)”, and then check the relevant boxes to specify the speakers you want to search.
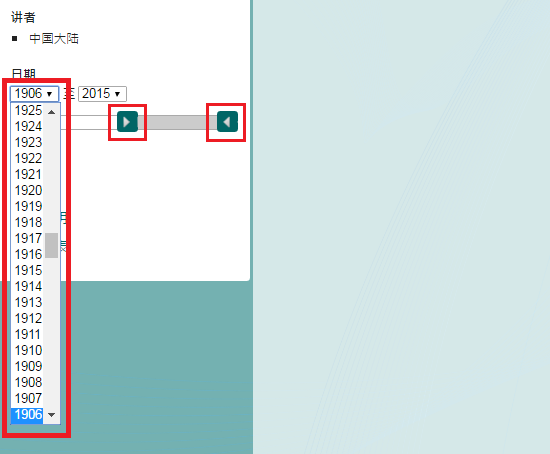
4. Specify the time range either by selecting the boxes or by dragging the green button to limit the retrieved data to a particular timeframe.
5. Press the “搜索(search)” button to get the result page.

6. View your search results with both No. of Occurrence in the relevant corpora and Graphical Representation to show the relevant percentage among all the search results.
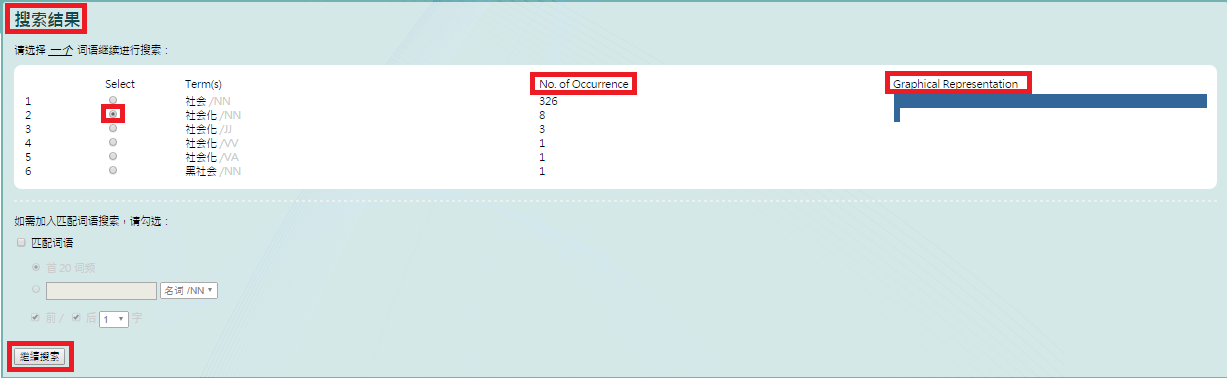
7. You can sort out “语句 (keyword in context)” by “年份(year)” / “地区(region)” / “类别(type)” / “讲者(speaker)”.
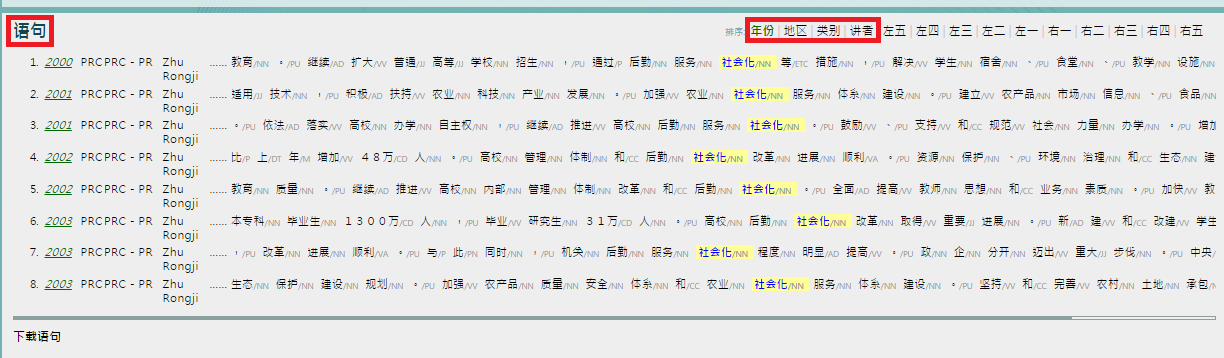
8. You can also sort out your “语句 (keyword in context)” by L1-L5 & R1-R5 (e.g. L1 is the first word to the left of the keyword).
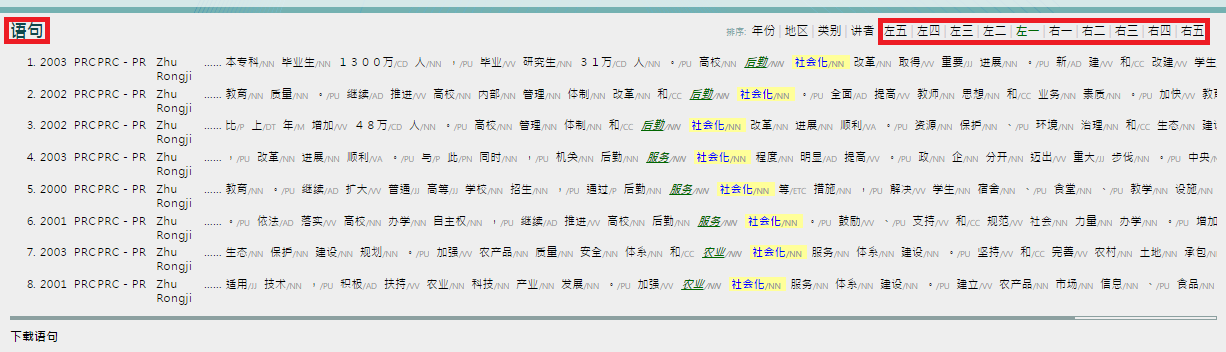
9. Click on any interested entries in step 8 to view “语句详细出处 (keyword in expanded context)”.
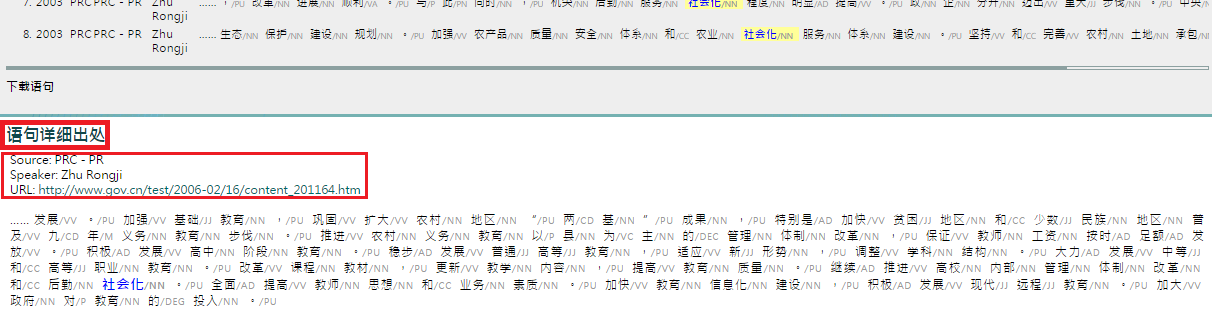
10. Click the button “下载语句 (download keyword in context)” to extract your data to an Excel document.

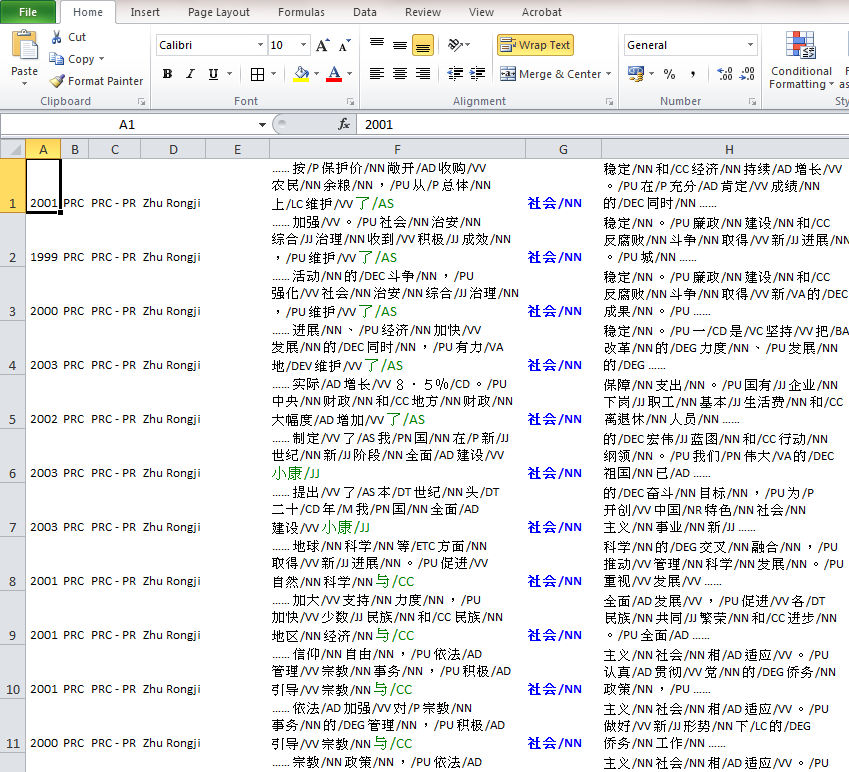
Collocation Function
After step 6, the collocation function becomes available in two approaches: either “首20词频 (top 20 words)” or “单匹配词 (single collocate)”.
1. 首20词频 (Top 20 Words)
a. Check the “匹配词语(collocation)” box, select “首20词频 (top 20 words)”, and then choose a number to specify its distance and position to the keyword, e.g. “1 & before”.
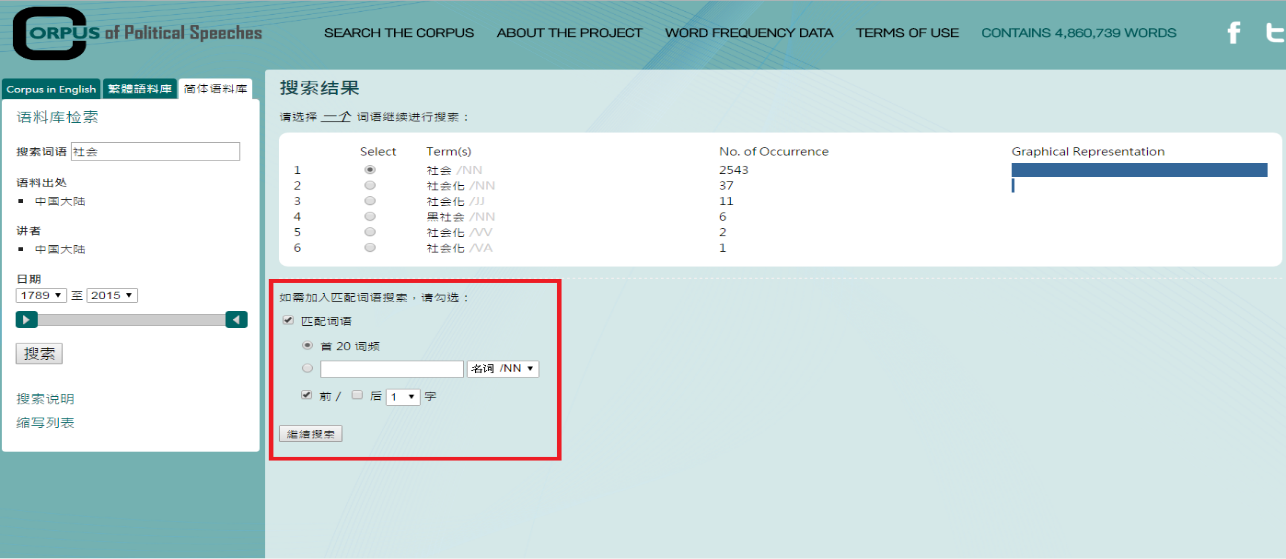
b. View advanced search results with No. of Occurrence and Graphical Representation, and then choose a collocate you need.
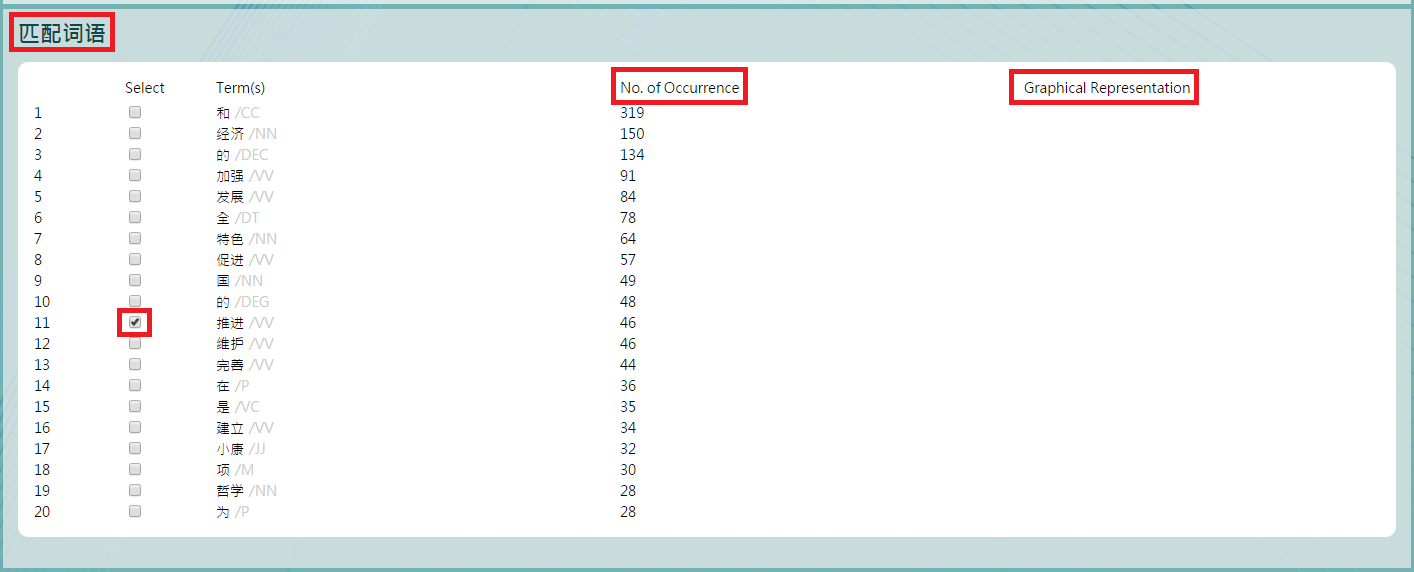
c. Output your results to Excel by clicking “下载语句 (download keyword in context)”.

2. 单匹配词 (Single Collocate)
a. Check “匹配词语(collocation)” box, input a single collocate with part of speech specified, e.g. “治安(security, n.)”, and then specify its distance and position to the keyword (e.g. “1 & After”).
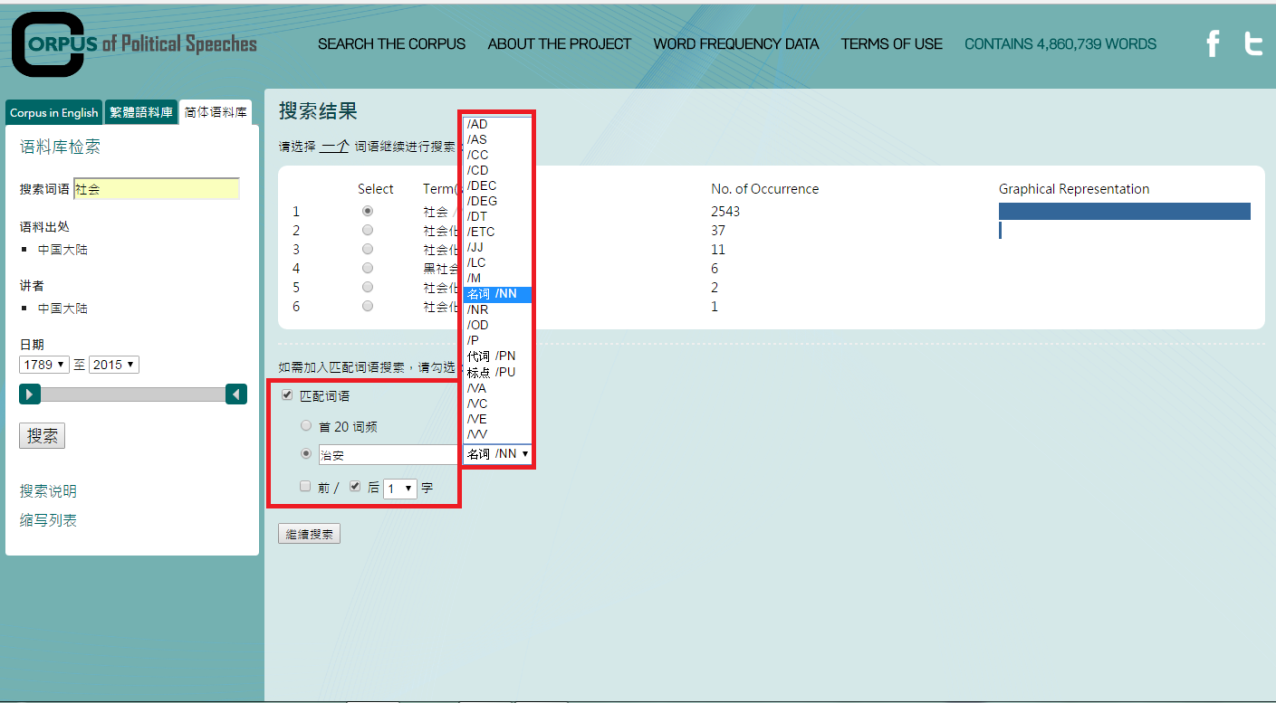
b. Click “继续搜索 (continue to search)” and view “语句 (keyword in context)” for further results.
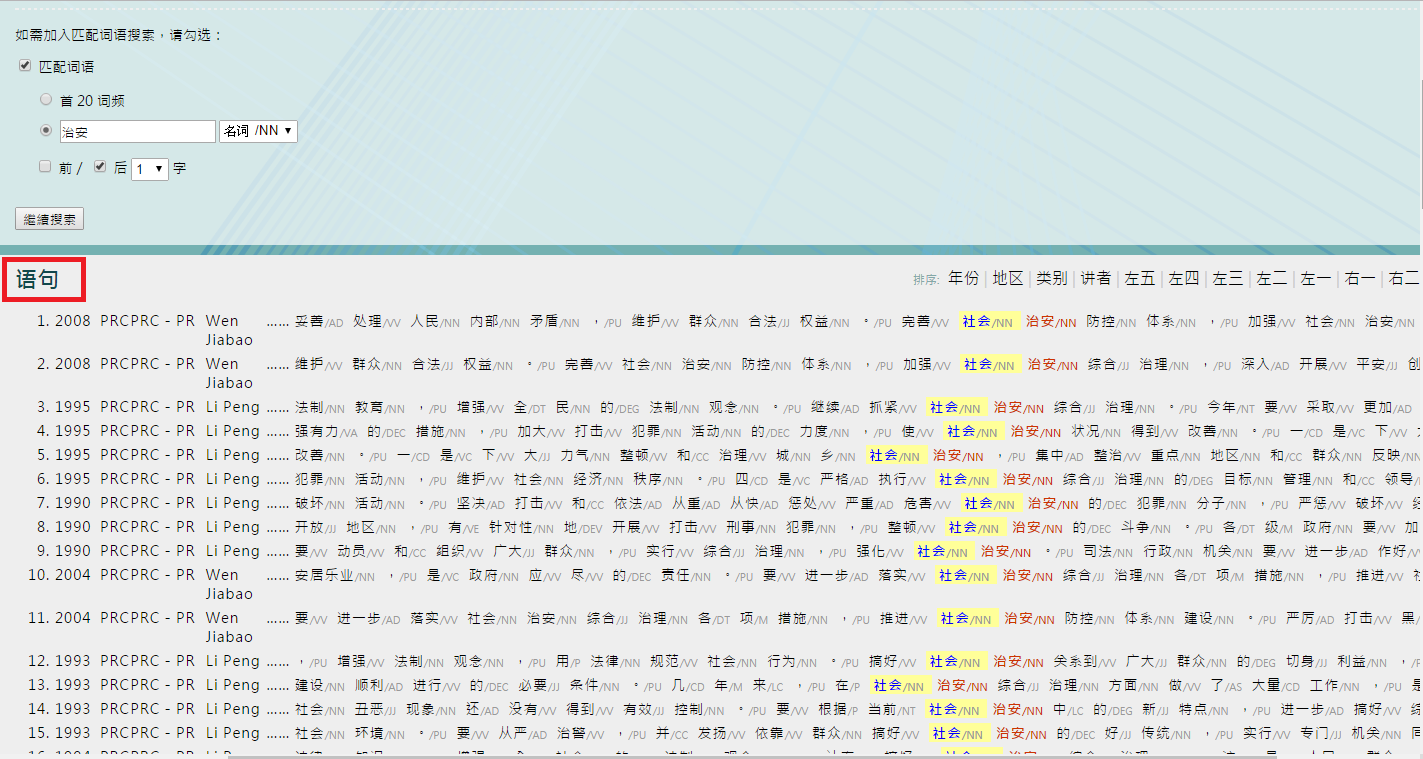
c. Output your results to Excel by clicking “下载语句 (download keyword in context)”.