How to Use the CEPIC
Keyword Search
1. Input a word in English or (Simplified/Traditional) Chinese you want to search in the corpus, e.g., “freedom” or “经济”/”經濟”. The corpus has the lexical associative function. Therefore, when you input characters/letters in the search box, the associative result will automatically display beneath the search box. You can also search a prosodic/paralinguistic feature, e.g., [er], when choosing the “annotated” version of the corpus (see the section Speech Transcription and Annotation).
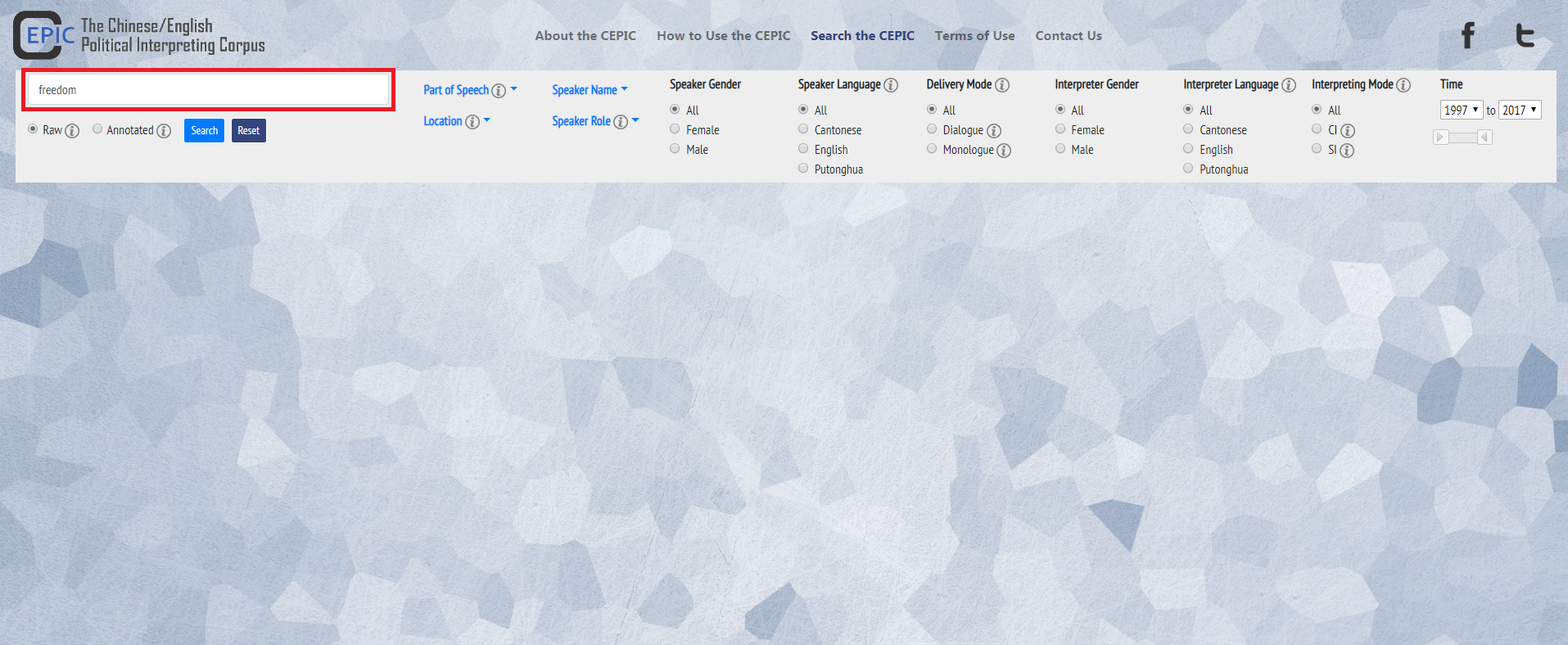
2. Adjust parameters for refining your search if you wish to: the “Raw” button will search in the official speech transcripts and their translations, and the “Annotated” button will search in the annotated transcripts of speeches and their interpretations. (Also refer to the section Glossary for the differences between Raw and Annotated)
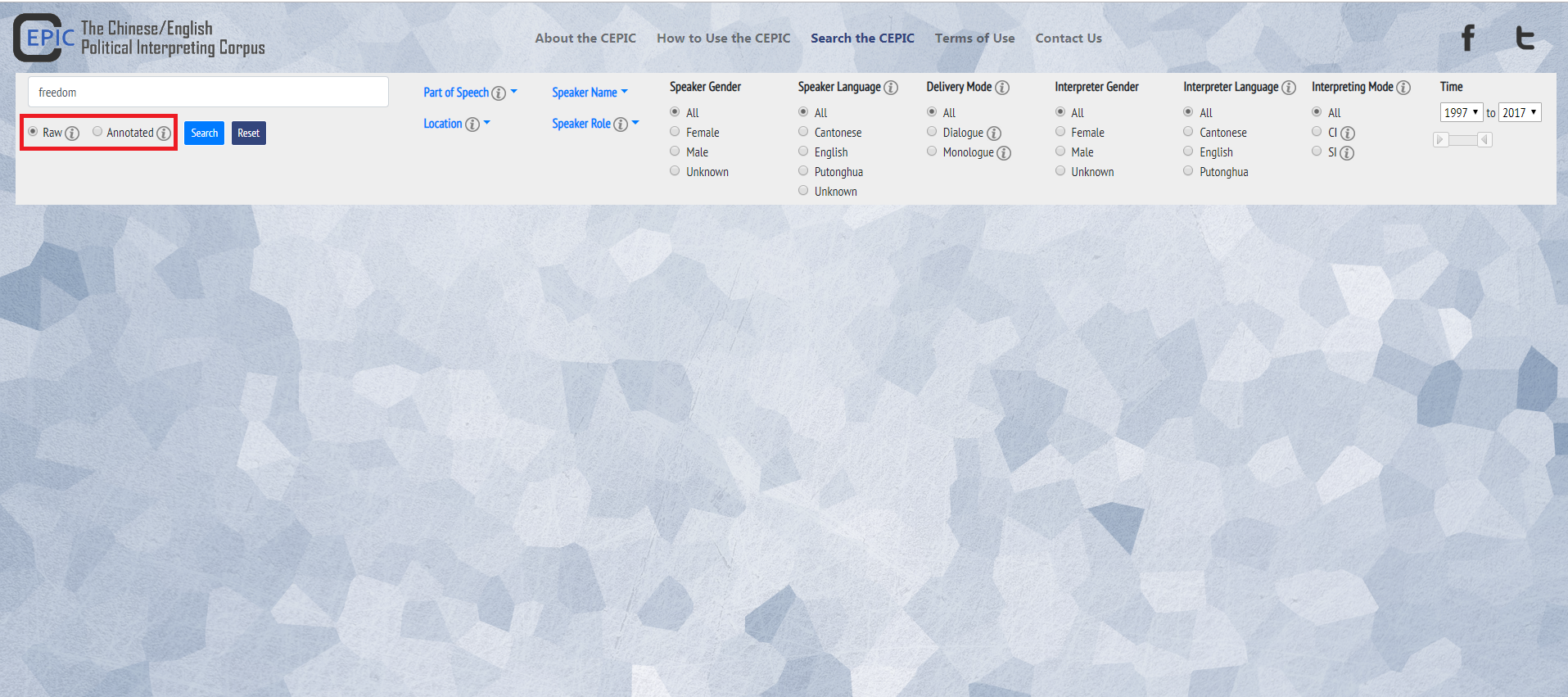
3. Adjust more parameters for refining the search if you wish to: Part of Speech, Location, Speaker Name, Speaker Role, Speaker Gender, Speaker Language, Delivery Mode, Interpreter Gender, Interpreter Language, Interpreting Mode, and Time Span (Also refer to the section Glossary for explanation of the filters). You can choose more than one option for Location, Speaker and Speaker Role, but only one option for the rest of the filters. Note that the default setting of a filter is “All” if you do not choose a specific category. You can choose “All” if you want to unselect the parameters. If you click on the “Reset” button, the search item and all selected parameters will disappear.
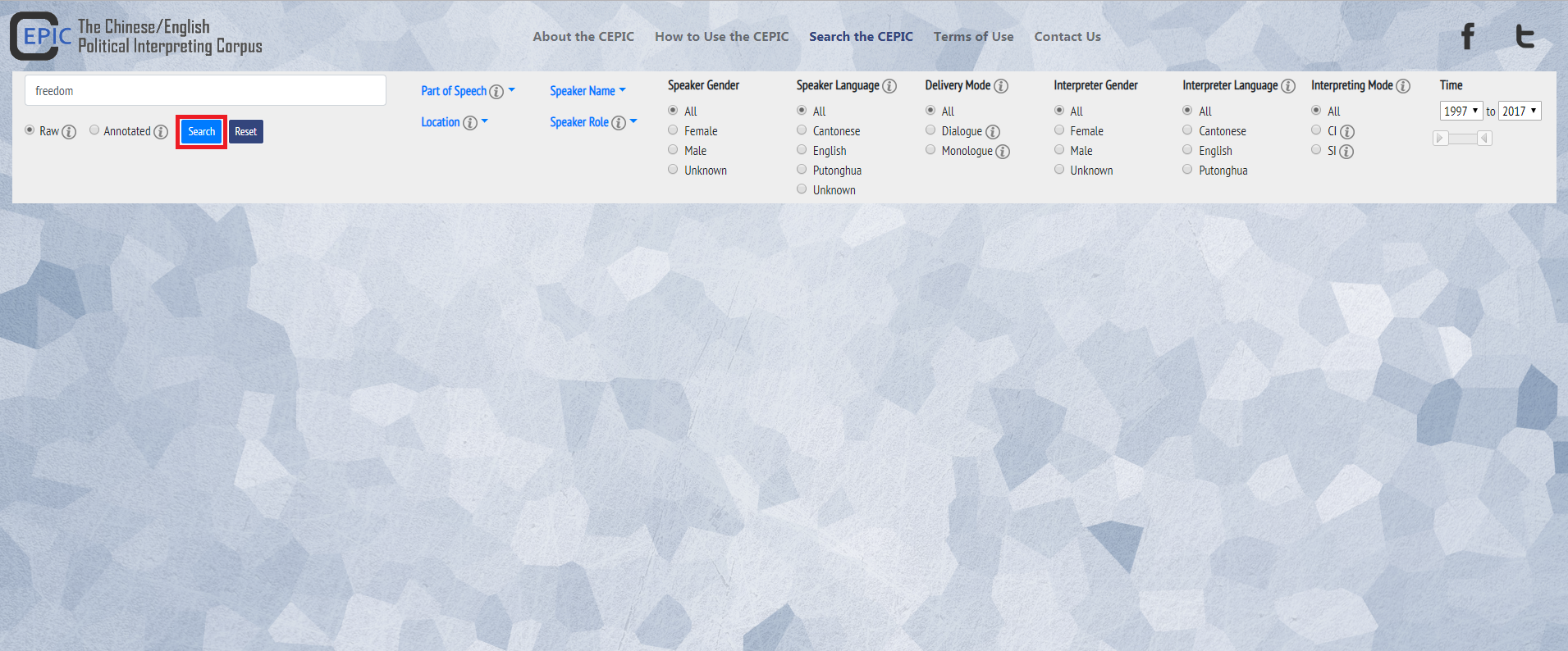
4. Press the “Search” button to get the result page.
5. View your search results with the number of records found in the relevant corpus set. The results can be arranged by Year, Location, or Speaker Name.
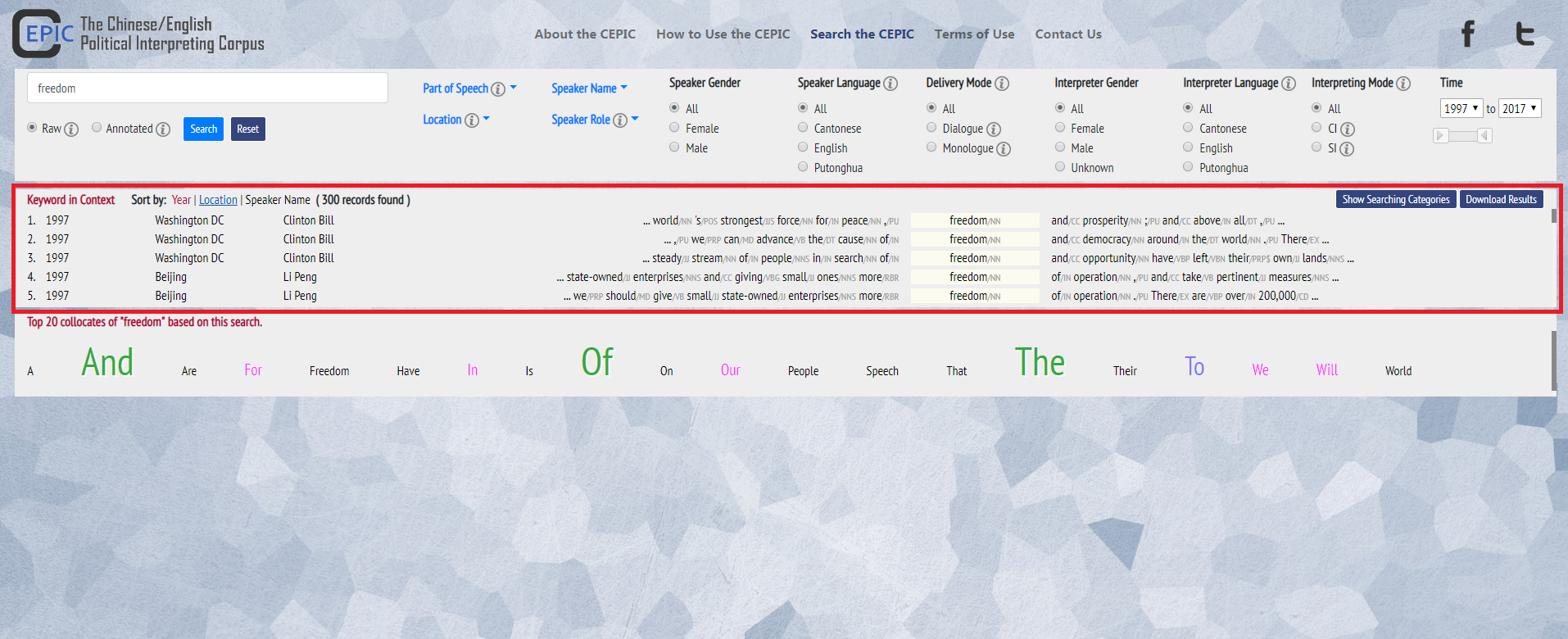
6. You can click on “Show Searching Categories” to obtain a list of the selected categories for this search. You can also download the results in excel format, by clicking on the “Download Results” button.
Back to Top
Word Collocation
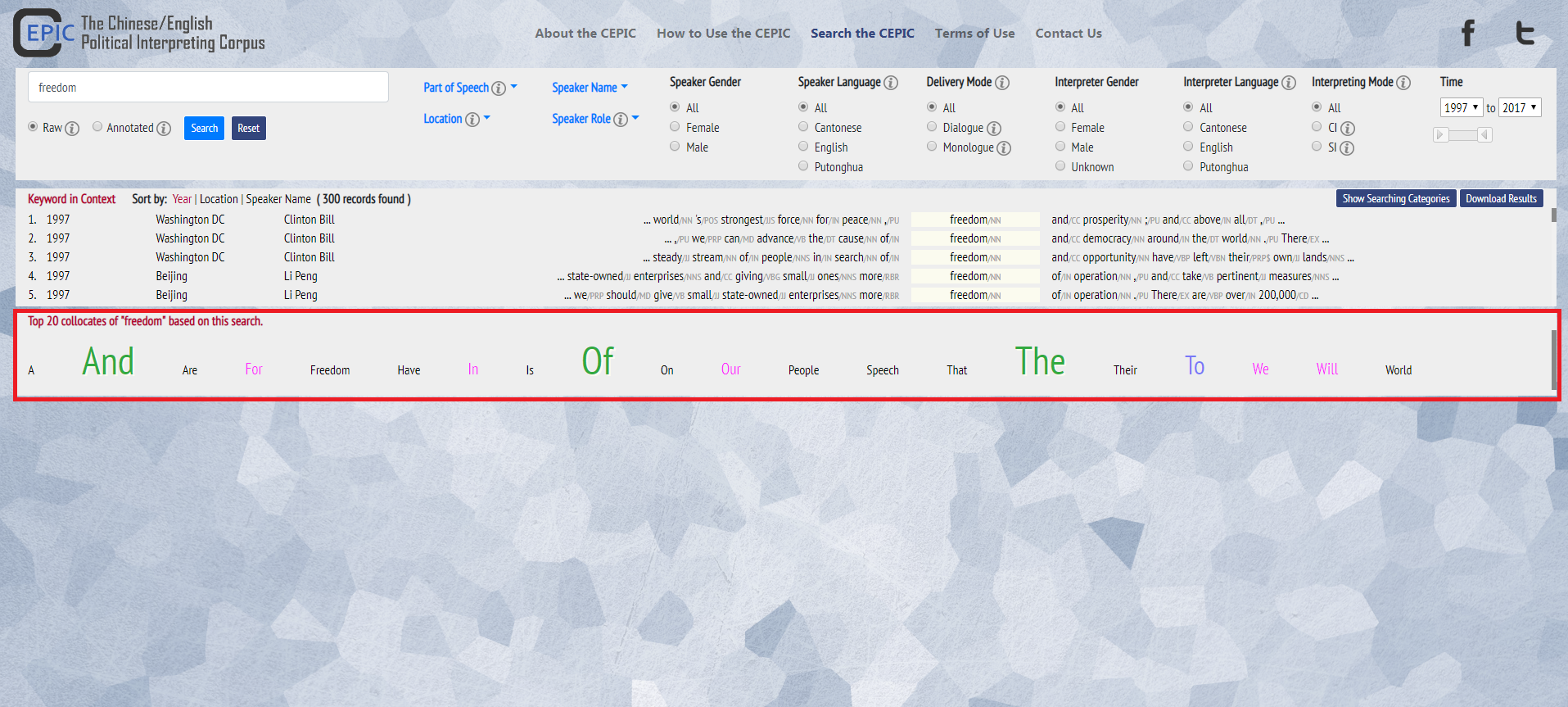
1. You can automatically obtain a list of the top 20 collocates of the queried word token. The collocation range is set as 7 words before and after the search term. The bigger the font size of the collocate, the higher the frequency it appears next to the queried word token.
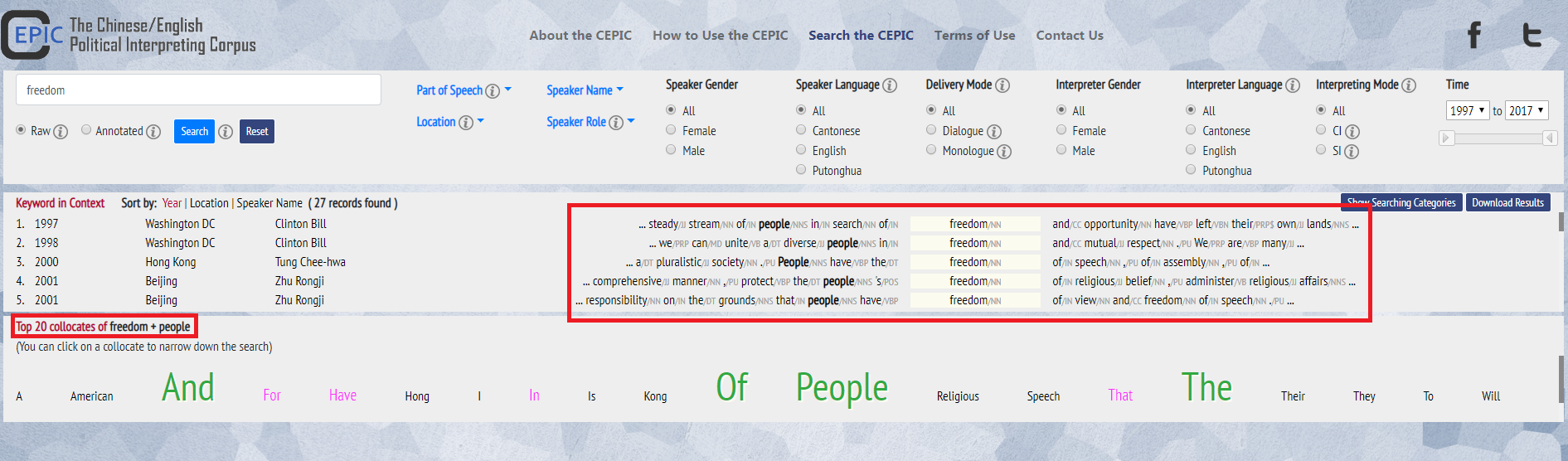
2. You can click on one of these collocates (e.g. “people”), and the concordance lines that included both the search term and the collocate (e.g., “freedom + people”) will appear under “Keyword in Context”. The top 20 collocates of “freedom + people” will be displayed.
Back to Top
Expanded Keyword in Context
1. Click on a keyword to obtain an Expanded Context, with the respective sub-corpora aligned.
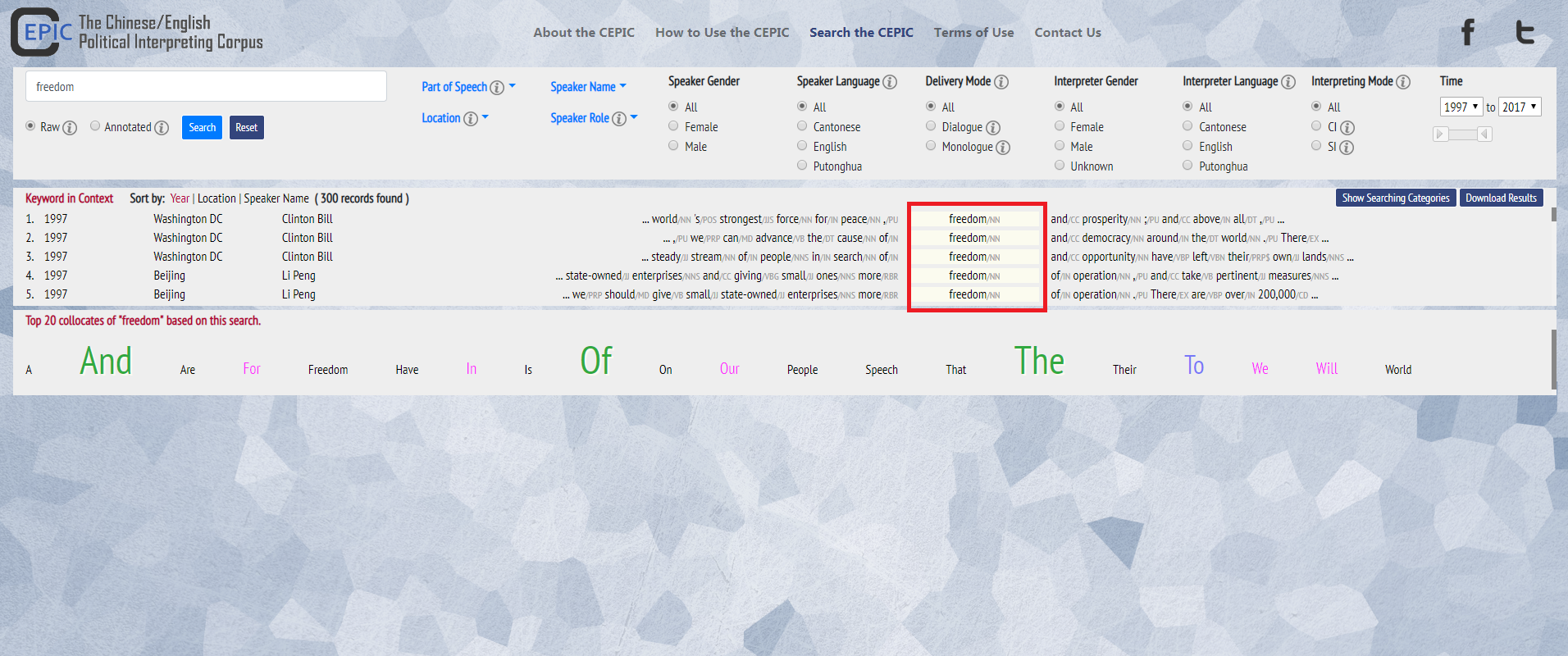
2. In the Expanded Context, you can find the detailed information about the selected Keyword.
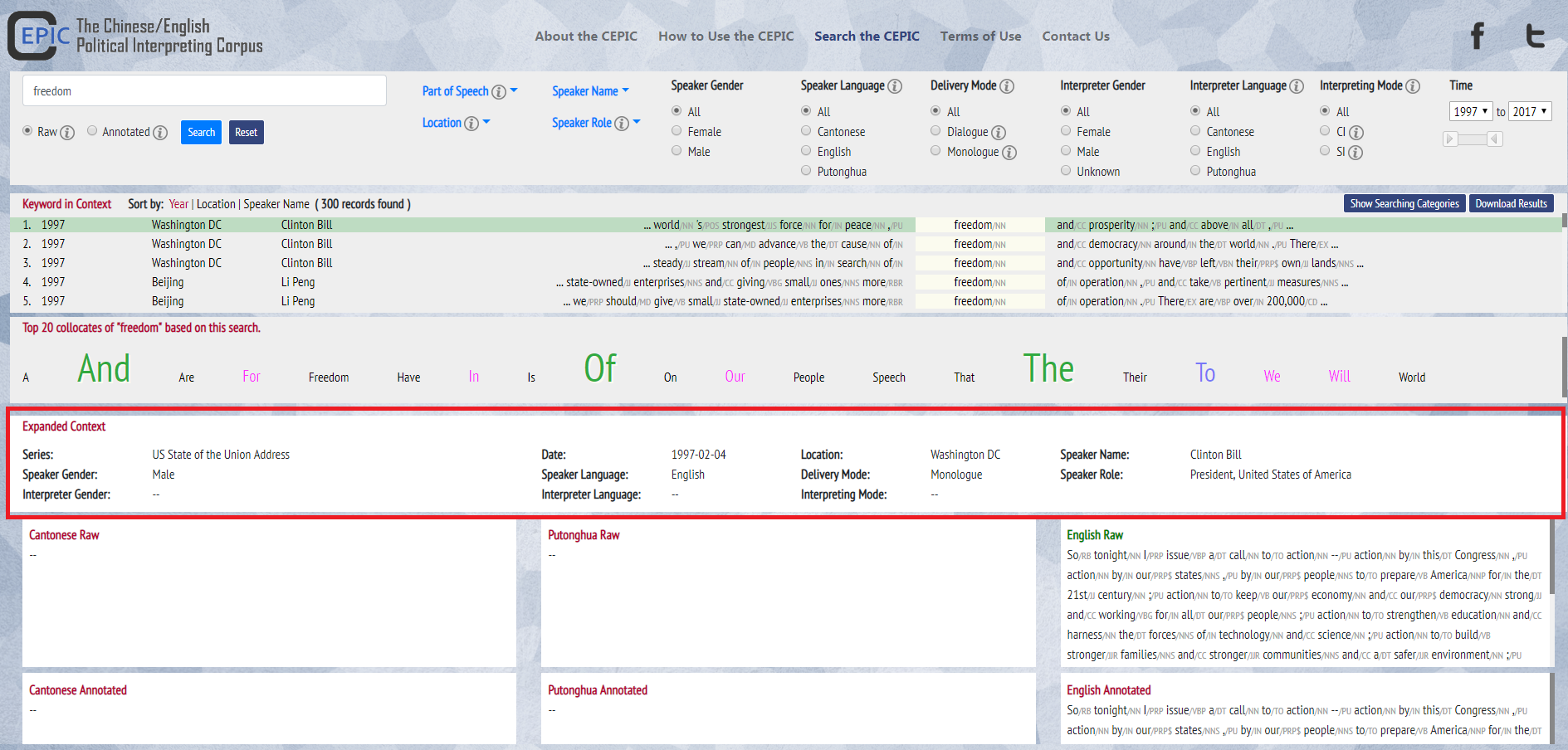
3. Under the Expanded context section, there are always six paragraphs. Depending on the nature of the results of the searched word token, some paragraphs will be empty. For example, if the keyword in context is found in a speech from Hong Kong, the six sections will have information (Cantonese Raw, Cantonese Annotated, Putonghua Raw, Putonghua Annotated, English Raw, English Annotated), whereas if the keyword in context is found in a speech from United States, or United Kingdom, only two sections will have information (English Raw, English Annotated). Note that sometimes the Annotated section will be empty, due to lack of audio-visual material to transcribe.
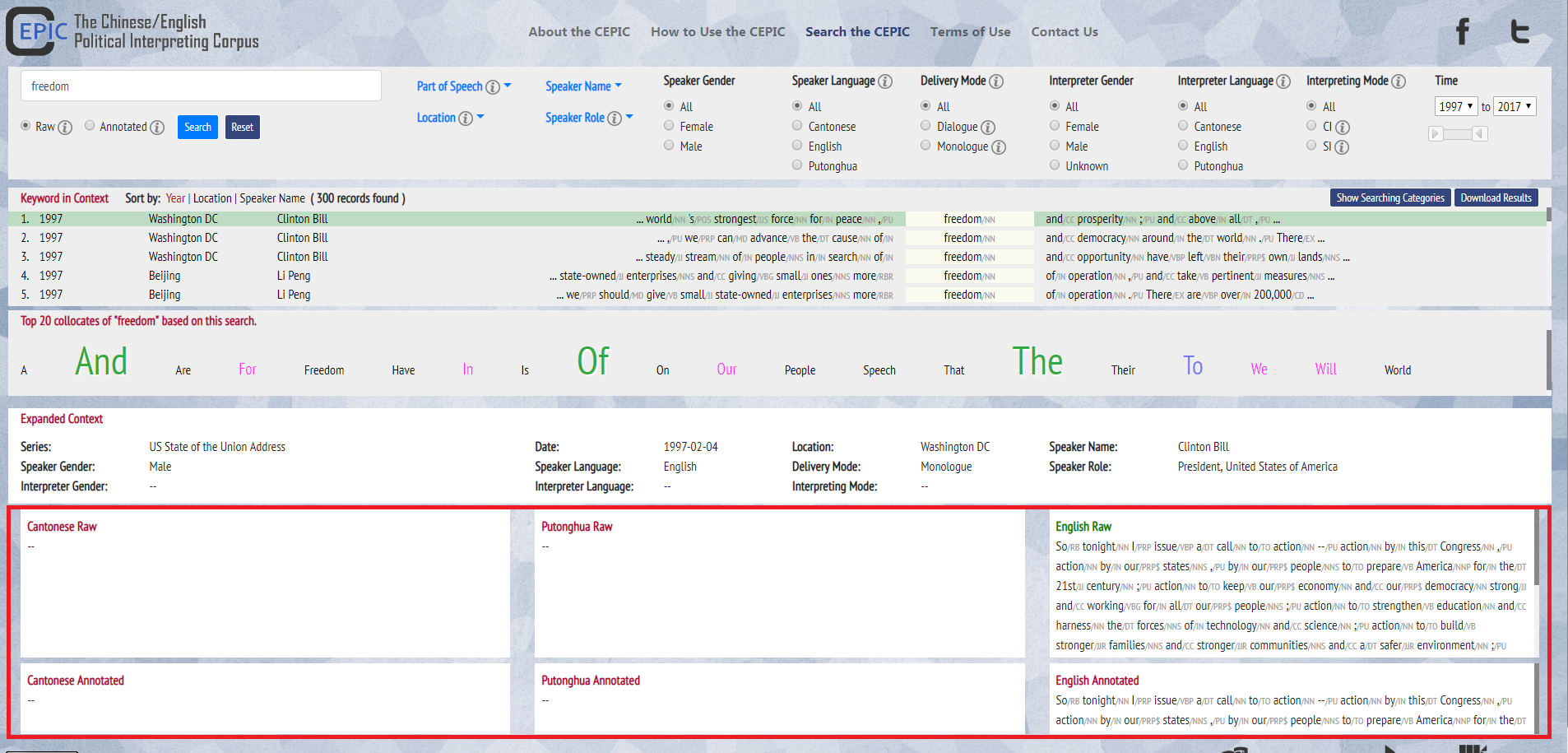
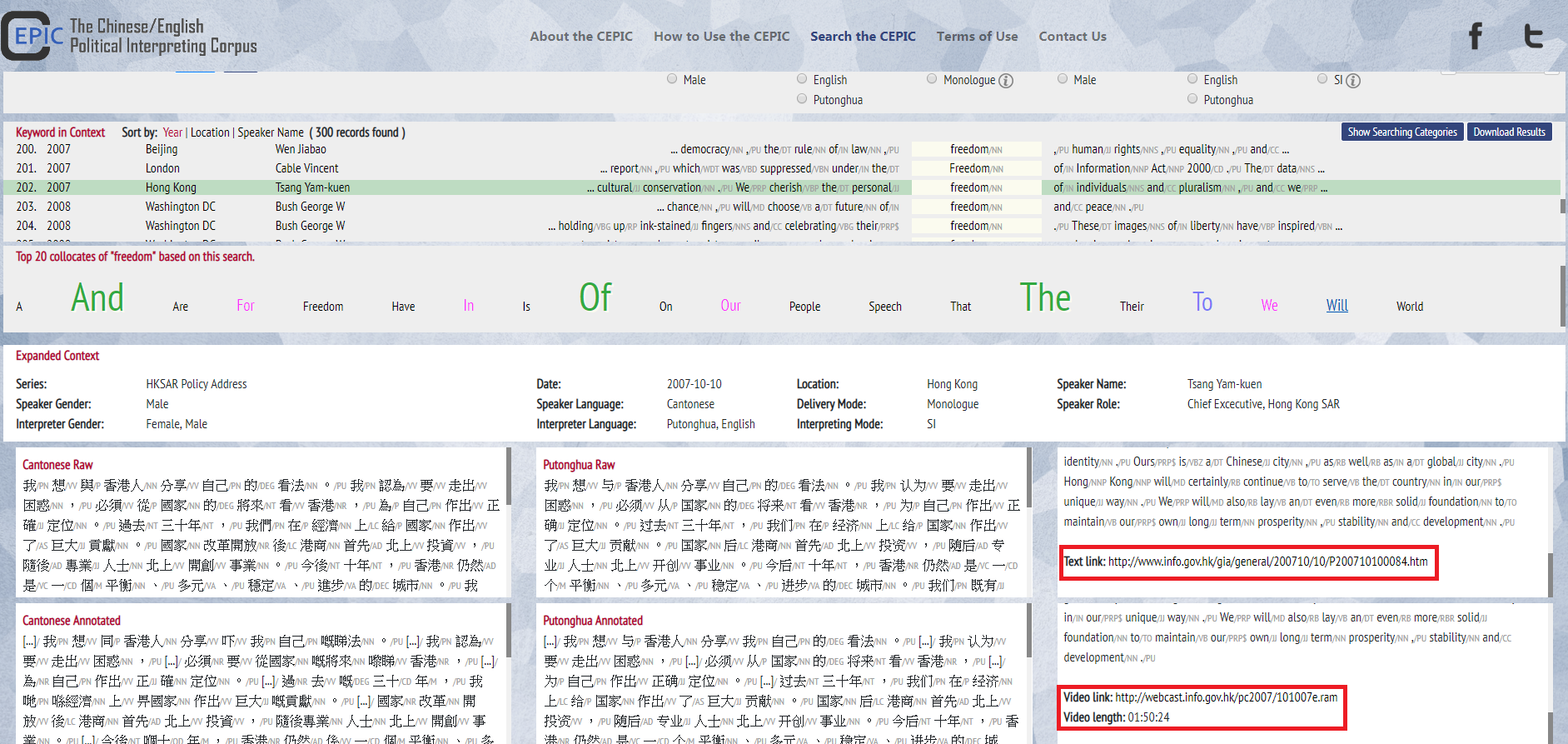
4. For every paragraph, there is a link that redirects to the original text (for the “Raw” version) or its audio/video (for the “Annotated” version; including information of the audio/video length).
Back to Top
FAQ
The following section lists some frequently asked questions relating to the CEPIC. You can also click on the icon popped up in some parts of the corpus for a detailed explanation.
popped up in some parts of the corpus for a detailed explanation.
If you cannot find answers to your questions here, please check https://sites.google.com/a/hkbu.edu.hk/cepic-the-chinese-english-political-interpreting-corpus/ for more recent updates about CEPIC, or follow our Facebook / Twitter account.
You are always welcome to send your questions/feedback to us via https://hkbuhk.ca1.qualtrics.com/jfe/form/SV_a97lXo4AKTh0hbT.
1. What is CEPIC?
The Chinese/English Political Interpreting Corpus (CEPIC), with about 6.5 million word tokens in size, is designed for the study of Chinese/English political interpreting and translation. It consists of transcripts of speeches delivered by top political figures from Hong Kong, Beijing, Washington DC and London, as well as their translated/interpreted texts.(Also refer to the section Introduction).
2. What are the differences between “Raw” and “Annotated” in the CEPIC?
The “Raw” part of the CEPIC refers to the speech transcripts and their translations collected from government websites, with no annotations of prosodic or paralinguistic features.The “Annotated” part of the CEPIC includes revised or newly transcribed texts (when there are no readily available transcripts) of political speeches and their interpreted texts based on audios/videos collected from government websites and TV programme archives. The texts were annotated with prosodic and paralinguistic features that are of concern to the study of spoken language as well as interpreting.
(Also refer to the section Glossary).
3. What are the differences between “Consecutive Interpreting” and “Simultaneous Interpreting”?
Consecutive Interpreting refers a mode of interpreting employed in political settings when the interpreter speaks after the speaker finishes (part of) his/her speech.Simultaneous Interpreting refers to a mode of interpreting employed in political settings when the interpreter speaks (usually in an interpreting booth) while the speaker deliveries his/her speech.
(Also refer to the section Glossary).
4. When is political interpreting/translation employed?
Political interpreting/translation is usually preformed for the reading of government reports such as policy addresses and budget speeches, Q&A at press conferences, parliamentary debates, as well as remarks delivered at bilateral meetings, etc., which are the main speech types included in the CEPIC.(Also refer to the section Introduction).
5. What is Part of Speech (POS)?
POS, also a word class, refers to the grammatical category a word belongs to. The CEPIC is POS tagged, i.e., each word is tagged with its part of speech.(Also refer to the section Glossary and the section POS tagging).
6. Is the full speech transcript/video available for the search results of a specific term?
Information of the sources of the speech transcripts is provided at the bottom of each textbox in the result page of “Keyword in Expanded Context”.You can access the full text of the relevant sources of the “Raw” version and the audio/video of which the “Annotated” version of the corpus was based on (including information of the audio/video length) via the URL links provided.
(Also refer to the section How to Use the CEPIC).
7. How to search a term?
You can enter an English or Chinese (Simplified/Traditional) word that you want to search in the search box. You can also search a prosodic/paralinguistic feature, e.g., [er], when choosing the “annotated” version of the corpus (see the section Speech Transcription and Annotation).You may consult the section Word Frequency Data for ideas on what word(s) you may want to search.
(Also refer to the section How to Use the CEPIC).
8. What filters can be applied to the searched results?
You have to choose either “Raw” or “Annotated” to start with. The default setting for all other filters are “All”. In case you want to limit your search results to a certain category, you can use filters including Part of Speech, Location, Speaker Name, Speaker Role, Speaker Gender, Speaker Language, Delivery Mode, Interpreter Gender, Interpreter Language, Interpreting Mode, and Time Span. (Also refer to the section Glossary and the section How to Use the CEPIC).
9. How are word collocates represented in the corpus?
The top 20 collocates of a search term are represented in the form of word clouds. The collocation range is set as 7 words before and after the search term. The bigger the font size of the collocate, the more frequent the word appears next to the search term. You can also click on a collocate, and the concordance lines that include both the search term and the collocate will appear.(Also refer to the section How to Use the CEPIC).
10. Can I download the search results?
Yes, you can always download and access your search results in an excel document, by clicking the button “Download results”. The search results can be sorted according to Year, Location, or Speaker Name.Please use the following format to cite the corpus/dataset:
Pan, Jun. (2019). The Chinese/English Political Interpreting Corpus (CEPIC). Hong Kong Baptist University Library, [Retrieved Date], Accessed from https://digital.lib.hkbu.edu.hk/cepic/
You need to note that use of the web-based concordance of CEPIC is only recommended for non-commercial research and educational purposes, instead of any commercial purposes.
(Also refer to the section Terms of Use). Back to Top